
Large Language Models (LLMs) have become one of the most influential technologies of recent years, powering tools like ChatGPT, Claude, Gemini and others. They can write code, answer questions, plan trips, summarise documents, and perform many other tasks. However, despite how natural and intelligent their outputs appear, the way these systems actually work is far less mysterious (though not less powerful) than it seems. In this article, I present how LLMs work under the hood.
1. Generative AI
Generative AI is a type of artificial intelligence designed to create new content, such as text, images, code, audio, video, from human prompts. It is commonly used in tools like chatbots, code assistants, image generators, content creation, etc. Generative AI systems, such as Large Language Models (LLMs), work by learning patterns from massive amounts of existing human data. During training, the model is exposed to billions of examples (like articles, books, websites, code repositories, forums, etc) and learns statistical relationships between elements in that data, and uses those patterns to generate something entirely new.
To understand how they achieve this, let's take a look under the hood of an LLM, and understand how raw text is transformed into tokens, how meaning is represented mathematically through embeddings, how attention mechanisms allow information to flow between words, and how stacked transformer blocks gradually build increasingly complex representations of language. From there, we’ll explore how these models are trained, how they generate responses, and why they sometimes produce incorrect or “hallucinated” information.
1.1 Generative AI vs Traditional Machine Learning
Unlike traditional machine learning systems, generative AI often does not require manually labelled datasets in its pre-training. In traditional supervised learning, humans typically label each example so the model can learn the correct output. For example, a dataset used to identify cats and dogs might contain thousands of images manually tagged with the correct animal.
Generative AI models are usually trained using a technique called self-supervised learning (this is not something exclusive to LLMs, it's a broader concept used across Generative AI). Instead of relying on human-created labels, the training data itself provides the supervision signal; for example, given a sequence of text such as: The capital of The Netherlands is ___, the model can use the next word (Amsterdam) as the correct answer. By repeating this process across billions of examples from multiple sources, the model gradually learns statistical relationships in text that correlate with language, facts, and concepts, and patterns without requiring humans to label every example.
This ability to learn from vast amounts of unstructured data is one of the key reasons modern generative AI became practical at scale. Rather than teaching the model individual facts one by one, developers provide enormous datasets and allow the model to discover statistical relationships on its own.
1.2 Generative AI Limitations
Generative AI does not “think” or “understand” in a human sense, and does not query a database to look up for answers. It can produce incorrect or misleading information, especially when the input is ambiguous or when it lacks reliable training examples. For this reason, outputs often need human review, especially in critical applications.
In summary, generative AI is best described as a probabilistic content generation system trained on large-scale data, capable of producing new and useful outputs by predicting patterns rather than reasoning like a human.
2. LLMs - Large Language Models
An LLM (Large Language Model), is a type of artificial intelligence designed to predict the next token in a sequence of text. It works by processing a sequence of tokens and producing a probability distribution over possible next tokens. There is no reasoning engine and no magic, it's "just" a very sophisticated function that looks at a sequence of tokens and outputs a probability distribution over what comes next. Its behavior emerges from learned statistical patterns in large-scale data.
LLMs are not reasoning engines or knowledge databases and they do not store copies of their training data. They learn abstract representations of language and concepts, allowing them to generate new and contextually relevant outputs that were never explicitly seen before.
Everything we associate with intelligence in these models (reasoning, creativity, code generation, problem-solving, language understanding, etc) emerges from doing next-token prediction at massive scale with massive data. It sounds reductive, but that's also the key insight. Once you understand the machinery behind that prediction, the behaviour that felt mysterious starts to make sense. With that in mind, let's walk through how data flows from raw text to generated output.
2.1. Tokenisation: text becomes numbers
LLMs do not process raw strings or words, they process tokens. Tokens are sub-word units that can represent individual characters, punctuation marks, or entire words. Before your prompt ever touches any neural network, a tokenizer converts the string into a sequence of integer IDs, one per token.
Context limits and API costs are measured in tokens, not words.
There is a reason why it processes tokens rather than split on spaces and use words, which is the open vocabulary problem. A word-level vocabulary breaks the moment it encounters something it hasn't seen: a typo, a proper noun, a term in another language, a new library name, etc. In that case, the model would need a catch-all “unknown” token, which removes useful information about the original text.
To solve this, modern LLMs use a sub-word tokenization approach. The most common method is Byte Pair Encoding (BPE). It starts by treating every word as a sequence of characters, then repeatedly merges the most frequent pairs of characters (or character sequences) until a fixed vocabulary size is reached. As a result, very common words are stored as single tokens, while rare or unseen words are split into smaller, reusable parts that the model already knows. For example, the word "intelligence" might be split into ["intelli", "gence"]. This way, the model can still understand and work with words it has never seen before.
To see how some models convert words into token, you can use the tool Tokenizer on OpenAI Platform website, which allow you to select a model and add texts, and will show how this text will be converted into tokens:

In this example, as we can see, 4 words were converted into 5 tokens. It split "Converting" into two tokens: "Con" and "verting", and the other words were converted to one token each. You can play with this tool and see how your texts will be converted into tokens, using different models.
As most models are trained predominantly on English, words in other languages get chopped into smaller, multiple byte fragments, meaning the exact same paragraph can cost 2x to 3x more to process in other languages.
2.2. Embeddings: numbers become meaning
After tokenisation, each token is represented by an integer index. However, integers lack geometric relationships, for example, token 123 is not "closer" or more related to token 124 in any meaningful sense. To perform semantic calculations and to do anything useful, every token index must map to a vector of floating-point numbers. This mapping layer is known as the embedding.
Modern LLMs assign an embedding layer ranging from 1,024 to 16,384 dimensions per token. These vectors exist within a high-dimensional continuous space where spatial relationships tend to reflect semantic meaning: tokens with similar contexts naturally cluster together. The vector for "king" sits much closer to "queen" than it does to "invoice". Antonyms sit consistently opposite one another, and words with equivalent meanings across languages land in similar regions.
This multi-dimensional geometry is entirely learned, never hand-coded by human engineers. The model discovers the ideal spatial layout automatically through its training process; whatever arrangement makes next-token prediction more accurate is reinforced. These continuous vectors are what actually flow forward through the rest of the network.
Think of it as a big invisible map where every word has a location. Words that share meaning are "neighbours", for example "doctor" sits close to "nurse", and sits far from "asteroid". The map was not drawn by hand, it emerged from the model learning which arrangement made next-token prediction most accurate.
3. Transformers - The Game Changer Architecture
With tokens converted into semantic vectors, the system needs an architecture capable of processing them dynamically. In 2017, the research papper “Attention Is All You Need”, authored by eight scientists and engineers working at Google, introduced the Transformer, a new deep learning architecture built on the attention mechanism proposed by Bahdanau et al. in 2014. This architecture is what made modern LLMs possible and represents a major shift in how natural language processing is performed. Instead of relying on recurrence (RNN) and convolution (CNN) neural networks, it is entirely based on attention
This architecture is based on three core concepts:
- An attention mechanism that allows tokens to interact dynamically and weigh the relative importance of neighboring data.
- A stacked block structure that applies these interactions repeatedly to assemble deeper, more abstract representations.
- Architectural variants that adapt the same core design for different roles, such as encoding, decoding, or a combination of both.
When text enters a Transformer, it is first split into tokens and converted into vectors (embeddings). These vectors then pass through multiple layers where attention allows each token to look at all other tokens and decide what is relevant. After several stacked layers, the model produces a contextual representation used to predict the next token.
In the example below, there is an illustration showcasing the previous models and the Transformers. Note that on Previous Models, it proccessed one word at a time, while the transformers process all the words at once, in parallel:
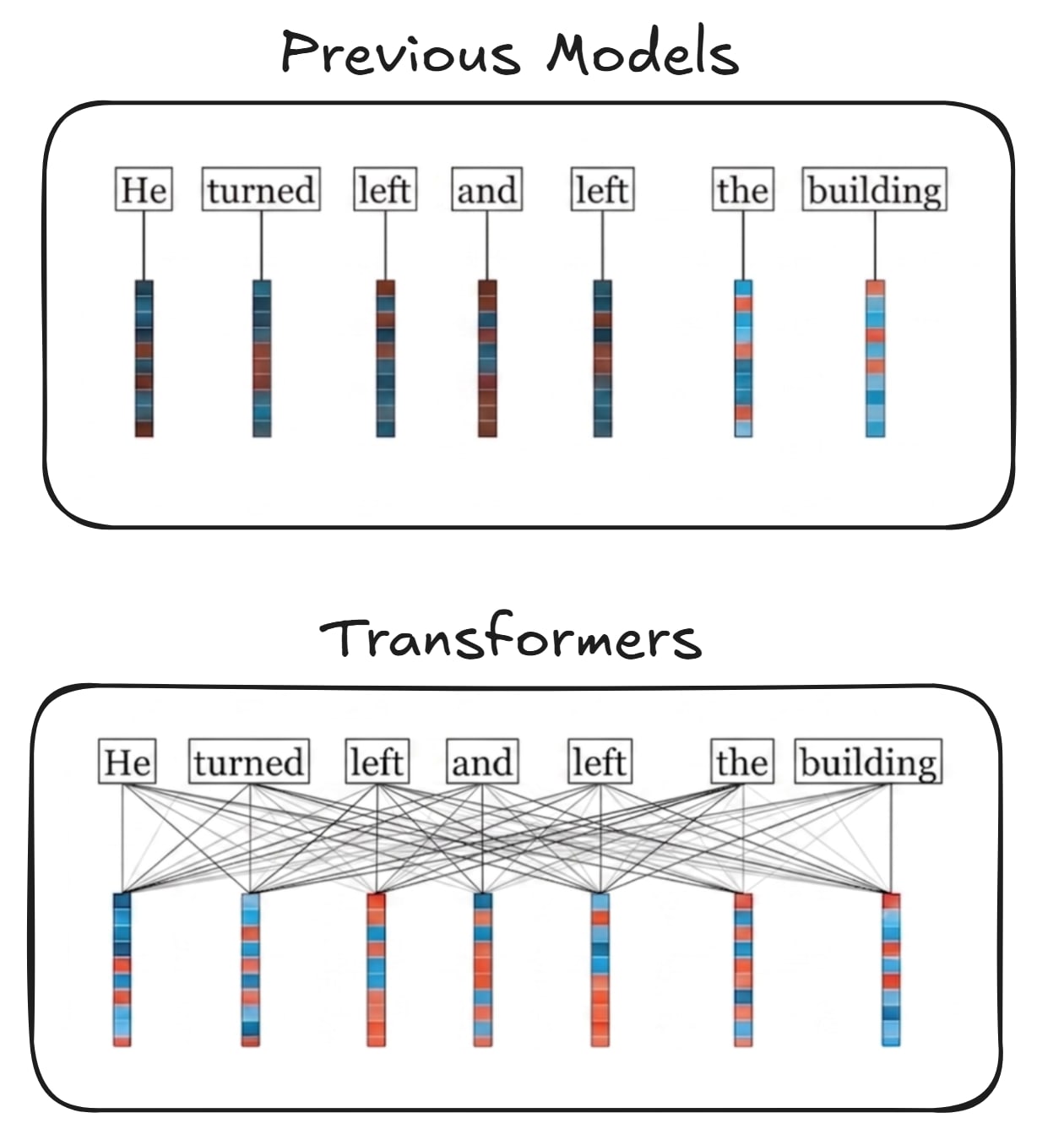
Before Transformers, the dominant approach was Recurrent Neural Networks (RNNs), which processed tokens one at a time, passing context forward through a single hidden state. This was slow and caused information to degrade over long sequences. Unlike RNNs, Transformers process all tokens in parallel, which makes training much faster on modern GPUs. This parallelization is one of the main reasons large language models became feasible at scale.
3.1. Attention: meaning meets context
In machine learning, attention is a mathematical method that calculates the relative importance of each component in a sequence compared to all other components in that sequence. In natural language processing, this importance is represented by dynamic weights assigned to each word in a sentence. For every word, the model calculates which other words in the sentence matter most and how strongly they influence the meaning.
While static embeddings provide a token with a foundational vector, the true meaning changes based on context. For example, the token "bark" means something entirely different in the phrase "the dog's bark" compared to "the bark of a tree", yet a base embedding assigns it the exact same values. The Self-Attention mechanism solves this by allowing every token to review the entire sequence, calculate which neighbouring tokens matter most, and update its vector representation accordingly.
For instance, in the sentence "The dog sat on the mat because it was tired", self-attention allows the model to map the pronoun "it" heavily to "dog". Every token looks at every other token in parallel, updating its vector to become a highly tailored, context-aware representation.
Different from RNNs, Attention computes pairwise interactions across all tokens in parallel: every token pair interacts directly, and the entire computation runs in parallel on GPUs, making billion-parameter scaling practical.
3.2. Positional encoding
As the Transformer processes all tokens in parallel, it is inherently order-agnostic. If you shuffle the tokens of a sentence into a random pile, the basic attention math produces the exact same statistical output (the exact same result). The model cannot tell the difference between "the lion hunted the zebra" and "the zebra hunted the lion" without help.
Positional encoding solves this problem by injecting an explicit position signal into each token's embedding vector before any attention operations take place. It adds a mathematical signal based on sine and cosine functions, to each token's embedding before the attention layers.
The original Transformer used sine and cosine functions at different frequencies to generate a unique pattern per position (position 1 gets one pattern, position 2 gets another, and so on). These signals are added directly to the token embeddings, so every vector now carries both "what this token means" and "where it sits in the sequence."
Modern models often replace fixed sinusoidal encodings with learned positional embeddings (the model learns the best position representations during training) or with RoPE (Rotary Position Embedding), which modifies the system by rotating the Query and Key vectors in complex space based on their relative distance from one another rather than applying an absolute coordinate. The mechanism varies, but the goal is always the same: give the parallel attention layers a sense of order without breaking their ability to process all tokens simultaneously, without sacrificing processing speed.
With positional encoding in place, each token's vector carries both semantic meaning (from the embedding layer) and structural position. This combined signal is what flows into the attention mechanism.
3.3. Q/K/V: the intuition
Inside the self-attention layer, text stops acting as a passive sequence. Every token dynamically broadcasts three distinct mathematical vector signals to its neighbors:
- Query: "What semantic properties am I looking for?",
- Key: "What properties does this token contain that others can match against?"/"What context or characteristics do I offer?",
- Value: "What core meaning do I actually carry?"/"The information content that will be passed forward if attended to".
The model computes how well each Query matches every Key, converts those scores into attention weights, and then uses those weights to blend the corresponding Values together. The result is a new context-aware representation for each token, where relevant information from other tokens has been incorporated. For example:
- In the phrase
"she played the lead role", the Query for"lead"calculates a powerful mathematical match with the Key for"role"(matches heavily with the Key of"role"). It pulls in the theatrical Value, shifting its final vector toward acting. - In the phrase
"the pipes were made of lead", the Query for"lead"calculates a strong match with the Key for"pipes". It pulls in the material Value, shifting its final vector toward heavy metallurgy.
The same raw token produces different representations depending on the context, driven entirely by the attention mechanism.
3.4. Multi-head attention
A single Query/Key/Value matrix pass can only track one type of relationship at a time because its internal weights are fixed for that step. To capture the full complexity of human language, models use Multi-Head Attention.
This technique splits the embedding dimensions into smaller subsections and runs several independent Q/K/V operations completely in parallel. Each individual "head" (an independent attention mechanism within multi-head attention, each learning to focus on different patterns in the same input), is free to specialise in a different linguistic relationship: one head might track subject-verb agreement, another resolves pronoun references/coreference, while a third monitors physical proximity or tense/topic proximity. The outputs of these independent heads are concatenated and projected back to the original size, giving the model several distinct conceptual lenses on the exact same phrase simultaneously.
3.5. Putting It Together: The Transformer Block
A Transformer block is composed of two main sublayers: self-attention and a Feed-forward network (FFN), each wrapped with residual connections and layer normalization.
The self-attention sublayer is where tokens interact and exchange contextual information. This is where mechanisms like Q/K/V projections, multi-head attention, and positional encodings (applied earlier in the pipeline) come together to produce context-aware representations. The FFN sublayer then processes each token independently, refining the representation produced by attention.
A Transformer block is the core repeating structural unit of an LLM, divided into a distinct two-stage pipeline:
- Attention (The "Talking" Phase): this is where tokens talk to each other and gather context from the rest of the sequence (broadcasting their Q/K/V signals to communicate with their neighbours, gather contextual details, and establish relationships). It determines which other tokens are most relevant and how much influence they should have. In a nutshell, this is where tokens look around, talk to their neighbours, and gather context. It decides with whom each token relates.
- Feed-Forward Network (FFN): If attention is where tokens talk to each other, the FFN is where each token is transformed independently through a learned nonlinear function. It is a small neural network applied independently to every token. After attention gathers information from the rest of the sequence, the FFN processes that contextualized representation through a learned mathematical function, refining and transforming it further. There is no interaction between tokens at this stage; each token is processed in isolation.
In a nutshell, attention decides which information to gather, while the FFN decides how that information is refined and represented.
A modern LLM stacks dozens to hundreds of these transformer blocks in sequence. Nobody hand-designs what each layer learns: early layers tend to capture syntax and surface patterns, while later layers encode more abstract semantics and patterns associated with reasoning tasks. This hierarchy of representations emerges entirely from training on large-scale data.
This deep stacking is made possible by a key architectural feature named Residual connections. As information flows through many layers, it can otherwise degrade or become difficult to propagate. To prevent this, each sub-layer adds its input directly back to its output (output = layer(x) + x), creating a “highway” for information and gradients. This allows very deep networks to train reliably while preserving useful signals from earlier layers.
3.6. Model families
The same transformer block can be assembled in three main ways, each suited to a different class of tasks:
- Encoder-Only (BERT, RoBERTa, DeBERTa), uses bidirectional attention, meaning every token can attend to every other token in the input simultaneously. This makes it highly effective for understanding tasks such as classification, sentiment analysis, semantic search, and named entity recognition. These models are generally lighter and faster, but they cannot generate text autoregressively/freely.
- Decoder-Only (GPT-4, Claude, Llama, Gemini), uses causal (left-to-right) attention, where each token can only see/attend to previous tokens. This structure enables autoregressive generation, producing text one token at a time. It is the dominant architecture for modern chat models, code assistants, and general-purpose LLMs.
- Encoder-Decoder (T5, BART, mT5), the encoder processes/read the full input sequence, while the decoder generates an output conditioned on that encoded representation. This is particularly effective for sequence-to-sequence tasks such as translation, structured summarization, and rewriting.
4. Training: learning from prediction errors
Now that we understand the physical machinery of the Transformer block, you could be wondering how we tune its billions of internal parameters to generate accurate responses? This is accomplished by training.
A model needs to be trained, and for that, the model is exposed to a huge amount of data, like articles, books, websites, code, forums, talks, etc, which are all used to train the model.
The initial pre-training phase can be performed without human intervention, as the learning signal is derived directly from the text itself through self-supervised learning (the model can understand the data, check the patterns and can be trained by itself). However, later stages such as fine-tuning and RLHF may involve curated human data or preference feedback to shape the model’s behaviour.
This training process is accomplished across three distinct lifecycle phases.
In modern LLMs, the training process is accomplished across three distinct lifecycle phases, which are usually separate stages in a pipeline, and most systems use all of them in sequence:
-> Pre-training
-> Fine-tuning / Instruction tuning
-> RLHF (alignment)Pre-Training: This is where the model acquires its foundational world knowledge. It reads large-scale text data containing billions or trillions of tokens from sources such as web pages, books, articles, code repositories, and other publicly or licensed available text, with a single, clear goal: predict the next token. This stage operates entirely on self-supervised learning, the text itself provides the answer key, eliminating the need for manual labels. After every single prediction, the model's error is measured, backpropagated through all the transformer layers, and the weights nudge slightly in the right direction, to reduce future error. This phase requires months of specialised computation and millions of dollars. Repeat this for a huge number of times, and the model learns grammar, facts, world knowledge, and reasoning patterns.
Fine-tuning: it takes a pre-trained model and continues training it on a smaller, curated dataset. While pre-training teaches the model general language patterns and knowledge, fine-tuning steers its behaviour toward a specific use case, such as a chat assistant, code assistant, classifier, or domain-specific expert. It is much cheaper than training a model from scratch because it builds on an existing foundation rather than learning everything from zero. Efficient approaches such as LoRA (Low-Rank Adaptation) add small trainable matrices instead of updating all model weights, dramatically reducing computational cost.
RLHF (Reinforcement Learning from Human Feedback): This alignment stage is typically done in multiple steps. First, the model is fine-tuned on a curated set of human-written demonstrations (supervised fine-tuning), which helps it produce more natural and instruction-following responses. Next, human evaluators rank multiple model outputs, and these rankings are used to train a separate reward model that learns to predict which responses humans prefer. Finally, a reinforcement learning algorithm (commonly PPO, although newer systems may use alternatives like DPO) uses this reward signal to further optimise the LLM, steering it toward responses that are more helpful, safe, and aligned with human expectations. This alignment stage helps bridge the gap between a capable next-token predictor and a practical assistant.
In some modern systems, PPO is replaced by more stable alternatives such as Direct Preference Optimization (DPO), but the core idea remains the same: learning from human preference signals.
The result is a shift from a general next-token predictor to a system optimized for usefulness and usability in real-world interactions.
5. Scaling Matters
The capabilities of modern LLMs did not come from a single algorithmic breakthrough alone. Research has shown that increasing three factors simultaneously: model parameters, training data and compute, leads to predictable improvements in performance, often called scaling laws. Many capabilities that appear intelligent emerge only after models reach sufficient scale.
6. Inference: controlling the output
Inference is the phase where the model uses its learned parameters to generate text (after the training is completed). After processing a prompt, the model produces raw scores (logits) for each token in the vocabulary. These scores are converted into probabilities using softmax, forming a distribution over possible next tokens.
Instead of selecting a single fixed answer, the model samples from this distribution using strategies such as temperature, top-k, and top-p, which control the balance between determinism and randomness.
During inference, the model takes a prompt from the user and applies everything it has learned during training to predict and produce new text, one token at a time. Unlike training, there is no backpropagation or weight updates; the model is essentially in “read-only” mode, generating outputs based on fixed parameters. At inference time the model outputs a probability distribution over the entire vocabulary for the next token.
For example, given the prompt "The sky is ___", the model might assign probabilities such as:
"blue"= 45%"clear"= 25%"dark"= 15%"cloudy"= 5%- and so on.
Generation is autoregressive: each selected token is appended to the growing sequence, and the model repeatedly runs to predict the next token. This step-by-step process continues until a stopping condition is reached. To prevent the model from always repeating identical paths, engineers rely on three main sampling parameters to tune its creativity:
- Temperature: scales the logits before they are passed through softmax. Values below
1.0sharpen the probability distribution, making outputs more focused and deterministic. Values above1.0flatten the distribution, increasing randomness, which can improve creativity but also raises the risk of incoherent outputs. A temperature of0corresponds to greedy decoding, where the model always selects the highest-probability token. A tip: Use low temperature for deterministic tasks (extraction, classification, structured output) and raise it to a higher number for creative work. - Top-k: restricts the model sampling to a fixed number, the
khighest-probability tokens. Only these tokens are considered for selection, while all others are excluded. - Top-P (Nucleus Sampling): selects the smallest set of tokens whose cumulative probability mass reaches
P. Instead of using a fixed cutoff, the candidate pool adapts to the shape of the distribution: when the model is confident, only a few high-probability tokens are included; when uncertainty is higher, the pool expands to include more options. This makes Top-p more flexible than Top-k and often produces more natural outputs.
The Context Window Limit: Because self-attention requires every single token to compare itself with every other token in the prompt, the computational memory requirements scale quadratically relative to sequence length. This creates a hard architectural limit called the Context Window ( the hard architectural limit on tokens the model can attend to at once — 8k, 32k, 128k, 1M, etc, depending on the model, and beyond it, the information is gone). Once your active prompt and generated history cross this hard ceiling, older tokens are discarded from active memory completely.
7. The LLM Pipeline - How Text Moves Through an LLM
Now that we have looked at the individual pieces of the puzzle, let's look at the complete roadmap by putting everything together in a diagram. Here is the exact lifecycle of a prompt under the hood, mapping how text flows through the network to generate a response step-by-step:
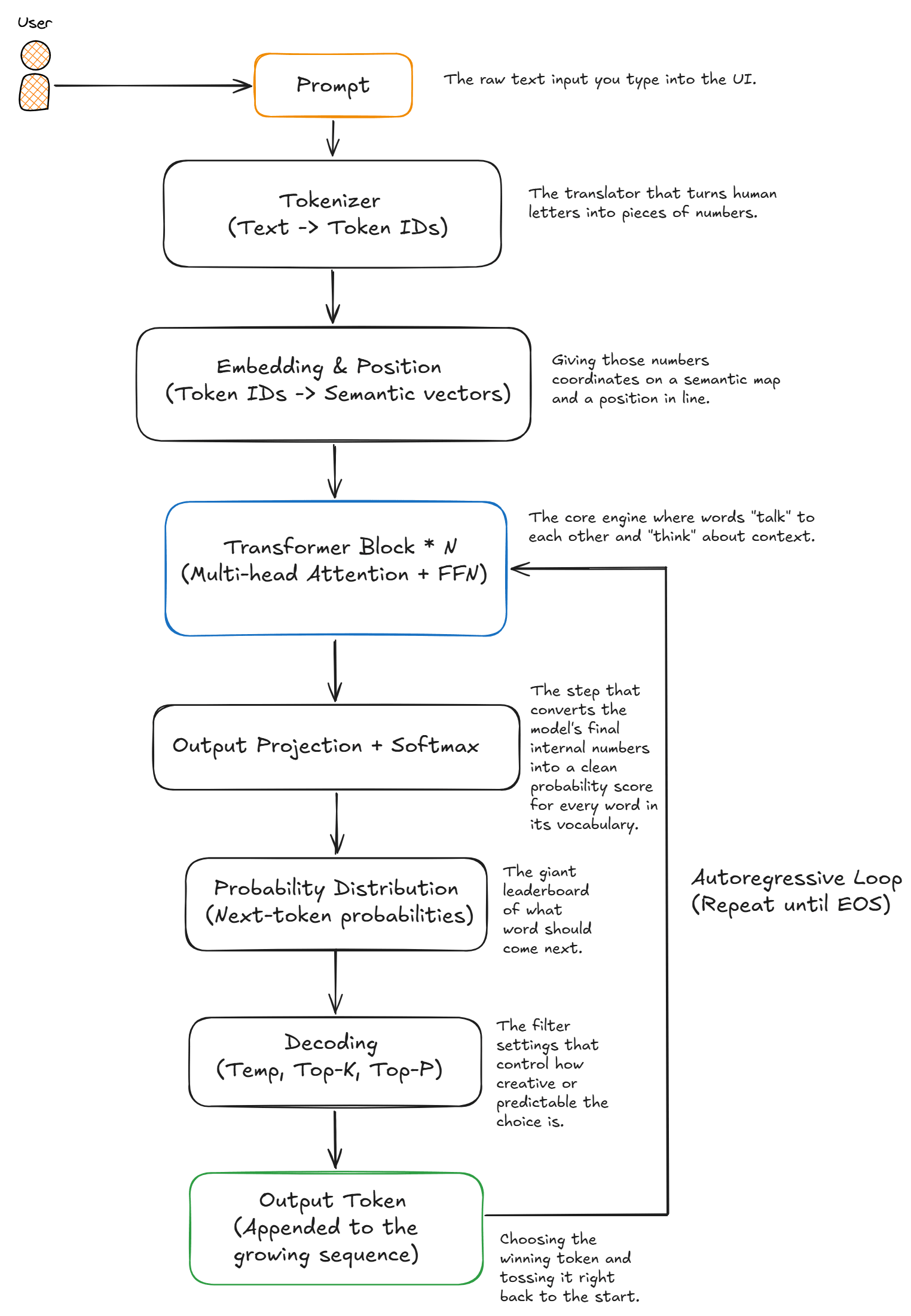
- User Prompt: the raw text input you type into the UI. This is the starting sequence. It sets the context, intent, and boundaries for everything the model is about to generate.
- Tokenizer: LLMs can’t directly process text. The tokenizer breaks text into sub-word units (tokens), typically using Byte Pair Encoding (BPE) or similar methods, and maps each token to a numerical ID in a fixed vocabulary.
- Embedding & Position: giving those numbers coordinates on a semantic map and a position in line. It transforms each token ID into a high-dimensional vector that encodes semantic meaning (that defines what the word means relative to other words). At the exact same time, it adds a mathematical signal (like RoPE) so the model knows where the word sits in the sentence structure.
- Transformer Block * N: the core engine where words "talk" to each other and "think" about context. This step repeats dozens of times. First, Multi-Head Attention lets tokens look at the whole sentence to figure out how they relate to their neighbors (e.g., matching "it" to "dog"). Then, the Feed-Forward Network processes that fresh context for each token in isolation, refining its meaning.
- Output Projection + Softmax: After the Transformer blocks finish processing the sequence, the model produces a contextual representation for each token. During generation, only the final token’s representation is used. This vector is passed through an output projection layer, which converts it into raw scores (logits) for every token in the vocabulary. Softmax then transforms these scores into probabilities, creating a distribution that ranks the most likely next token.
- Probability Distribution: the giant leaderboard of what word should come next. The final layer of the network looks at the processed vectors and calculates a percentage score for every single token in its entire vocabulary, ranking them from most likely to least likely.
- Sampling Parameters: the filter settings that control how creative or predictable the choice is. This is where Temperature, Top-K, and Top-P act as gatekeepers. They tweak the leaderboard, either locking onto the absolute #1 safest answer (low temperature) or opening the floor to wilder, less predictable choices (high temperature).
- Output Token: The model first produces a probability distribution over its entire vocabulary, assigning a likelihood to every possible next token. Based on the chosen sampling strategy (such as temperature, top-k, or top-p), one token is selected from this distribution. This selected token becomes the next piece of generated text.
- Autoregressive loop: this is the repetition mechanism that turns a single prediction into a full response. Instead of generating all tokens at once, the model generates text step by step. After producing one token, that token is appended to the input sequence (original prompt + all previously generated tokens), and the model runs again to predict the next token. This creates a loop where each new prediction depends on the full context built so far. The process continues until a stopping condition is reached, such as an End-of-Sequence (EOS) token, a maximum token limit, or a predefined stop sequence. To make this efficient, the model uses KV caching, which stores the Key and Value matrices computed for every previous token. On each new step, only the latest token needs to go through the full Transformer stack; all prior Keys and Values are read from cache, avoiding redundant computation and making long outputs practical without a linear slowdown. In a nutshell, the autoregressive loop means the LLM generates text like a high-speed typewriter rather than a printer.
8. Hallucinations: when fluency and truth diverge
The same capability that makes LLMs useful (generating fluent, plausible text) is exactly what makes them "dangerous" in contexts requiring factual precision. An LLM has no internal truth-checking. The same process that answers questions about quantum physics answers questions about Nobel Prize winners: in both cases, the objective is to produce plausible tokens sequences based on statistics, not verified data points.
When a model hallucinates, it usually falls into one of three buckets:
- Factual hallucination: The model states something objectively wrong with high confidence. Because the text flows naturally, readers lower their guard, making these errors difficult to spot.
- Source hallucination: The model invents papers, legal cases, citations, or quotes that do not exist, assigning them realistic author names and publication years.
- Reasoning hallucination: The model generates a plausible step-by-step argument that appears logically consistent but ultimately leads to an incorrect result. The fluency of the reasoning makes the error harder to identify.
Why this happens: The model has no built-in world model or factual database to verify information. Instead, it relies on learned statistical patterns from text. When a prompt falls outside well-represented regions of its training data, the model extrapolates from these patterns rather than refusing to answer, which can lead to plausible but incorrect outputs.
Mitigation Strategies: Hallucinations can be reduced by grounding the model with external, verifiable information using RAG (Retrieval-Augmented Generation). This approach provides the model with relevant documents at inference time, helping it base responses on real data rather than internal memory alone. Additional techniques include requesting explicit source citations, using structured output formats to make reasoning gaps more visible, and lowering temperature for more deterministic outputs. In high-stakes domains such as legal, medical, or financial applications, LLM outputs should always be treated as a first draft requiring human verification.
LLMs are probability simulators of text, not truth systems.
9. RAG - Retrieval-Augmented Generation
One of the fundamental limitations of LLMs is that they rely entirely on what is stored in their trained parameters. They do not have access to an external, up-to-date source of truth, and they cannot reliably “look things up” the way a search engine or database can. This is where RAG (Retrieval-Augmented Generation) comes in.
RAG is a technique that extends an LLM by connecting it to an external knowledge source, such as a document database, vector store, web search, etc (or even proprietary internal databases). Instead of answering purely from memory, the system first retrieves relevant pieces of information related to the user’s query. These retrieved documents are then injected into the model’s context window as additional input. This can dramatically reduce factual and source hallucinations, and it also gives users a path to verify outputs (every claim can be traced back to a retrieved chunk).
In practice, this process works in two steps:
- Retrieval: The system first converts the user’s query into an embedding vector, using an embedding model to encode the query into vector space. This vector captures the semantic meaning of the query in numerical form. It is then compared against a database of pre-computed document embeddings using cosine similarity, which measures how closely two vectors align in high-dimensional space. The most similar documents are selected and passed to the model as additional context. In a nutshell, the system searches an external knowledge base and selects the most relevant documents for the query.
- Generation: The retrieved document chunks are injected into the model’s context window, typically prepended to the user’s prompt along with instructions such as “Base your answer on the information below whenever possible”. The LLM then generates a response conditioned on both the user query and the retrieved context. Because the model is grounded in external documents rather than relying solely on internal parameters, it is less likely to hallucinate factual details, and its outputs can often be traced back to the specific retrieved sources. In a nutshell, the LLM uses both the user prompt and the retrieved documents to generate a grounded response.
This significantly improves factual reliability, especially for domain-specific or rapidly changing information. Instead of relying only on patterns learned during training, the model is “anchored” in real data at inference time.
Note that RAG does not change the model’s internal weights. The LLM remains the same. What changes is the context it is given before generating a response. This makes RAG a lightweight and flexible way to improve accuracy without expensive retraining.
However, RAG is not a perfect solution. Its effectiveness depends on the quality of the retrieval system, the relevance of the selected documents, and how well the information is presented to the model. If the retrieval step returns poor or incomplete data, the final output can still be misleading. Also, if the relevant information is not in the data source, the retriever returns irrelevant chunks and the model either ignores them or hallucinates anyway (the quality of the retrieval step is the critical constraint).
RAG is the right choice when the knowledge changes frequently, is organisation-specific, or must be auditable. Fine-tuning is better when you need the model to adopt a specific style, follow a narrow output format, or deeply internalise a domain. In most real-world systems the sequence is: prompt engineering first → RAG for knowledge grounding → fine-tuning only when both are insufficient.
Conclusion
Large Language Models are not reasoning engines or knowledge databases, they are probabilistic systems trained to predict the next token. From tokenization and embeddings to transformers and attention, every component exists to support this single objective at scale.
What looks like reasoning, creativity, or understanding is actually the result of repeating this prediction process over massive amounts of data, producing coherent language one token at a time. However, because they optimize for statistical likelihood rather than truth, they can also generate incorrect or hallucinated outputs, which is something important to keep in mind when checking the outputs. In essence, LLMs are powerful pattern-completion machines: extremely capable at generating language, but fundamentally driven by statistical prediction rather than human-like understanding.
References
- Hugging Face
- OpenAI Tokenizer Platform Tool
- Attention Is All You Need
- Neural Machine Translation of Rare Words with Subword Units
- RoFormers: Enhanced Transformer with Rotary Position Embedding
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- LoRA: Low-Rank Adaptation of Large Language Models
- Proximal Policy Optimization Algorithms
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model
- The Curious Case of Neural Text Degeneration
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks


